
En la siguiente entrada vamos a crear un dataframe en Python leyendo un fichero Excel de una forma muy sencilla gracias a la librería pandas. Pero antes de todo, debes tener instalado Python, un interprete como Jupyter Notebook e instalar openpyxl . ¿Comenzamos?
Tabla de Contenidos
ocultar
Especificaciones del entorno
- Windows 11
- Python 3
- Jupyter Notebook
Paso previo
Para poder leer un fichero xlsx desde python primero debes tener instalado el modulo openpyxl. Abre tu símbolo del sistema e instálalo con el siguiente comando:
pip3 install openpyxl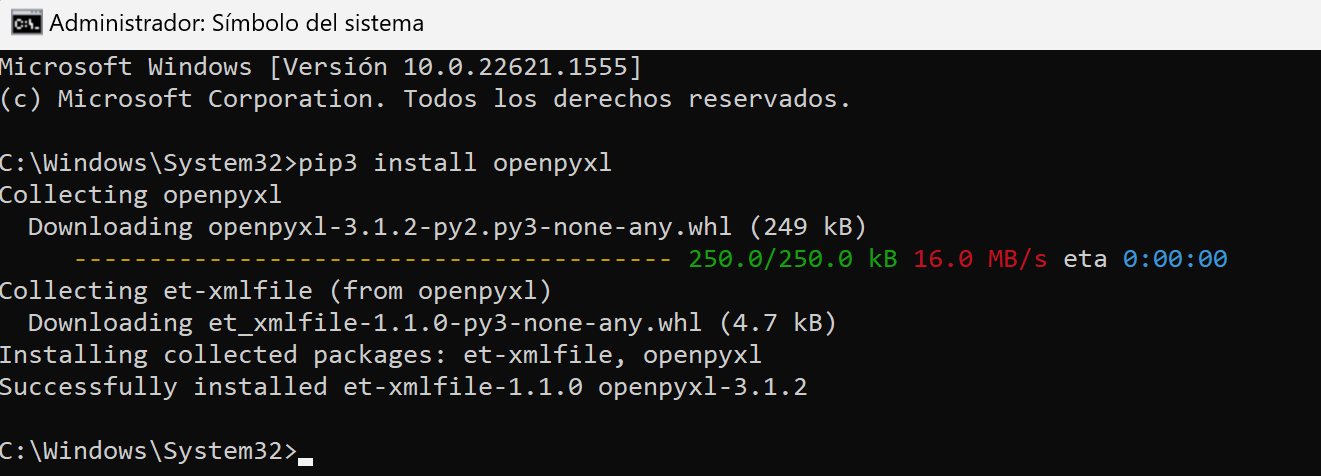
Paso a paso
Método 1: Leer un fichero excel usando el método read_excel() de pandas.
# importar librería pandas como pd
import pandas as pd
# leer la primera hoja del excel
dataframe1 = pd.read_excel('C:/tmp/Libro1.xlsx')
print(dataframe1)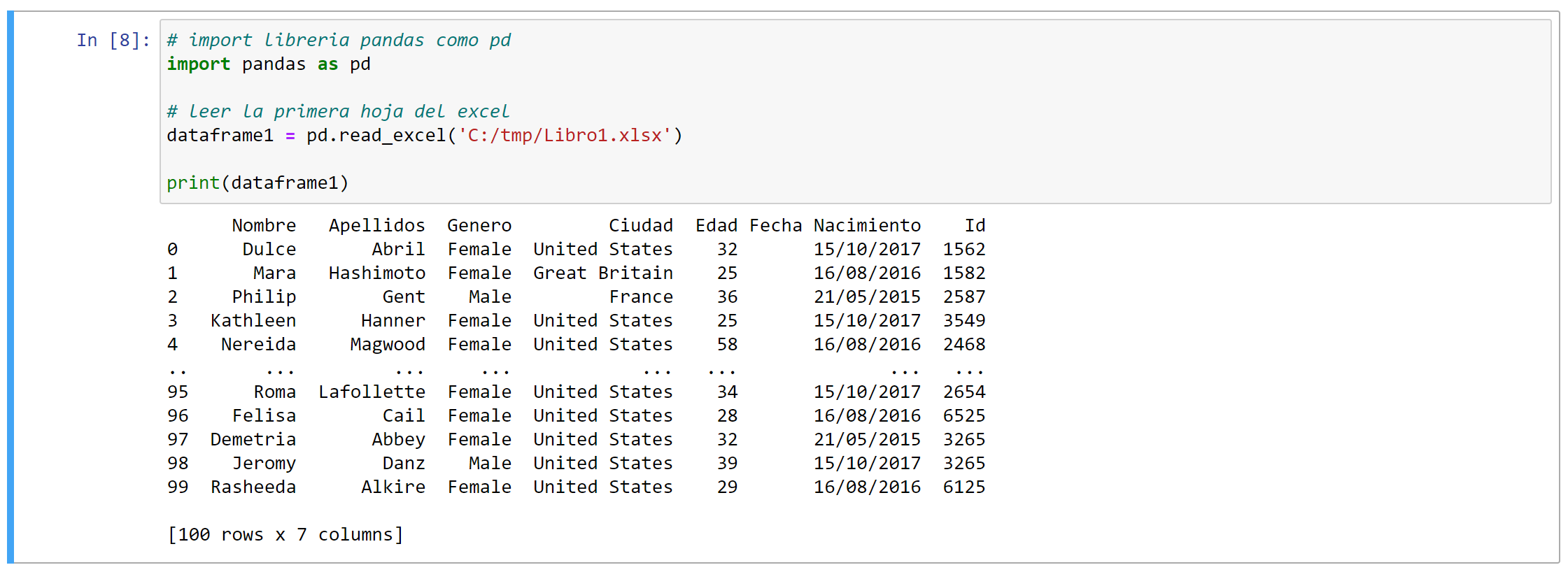
Método 2: Leer un fichero excel especificando la hoja
# importar librería pandas como pd
import pandas as pd
# leer la primera hoja del excel
dataframe2 = pd.read_excel('C:/tmp/Libro1.xlsx', sheet_name = 'Hoja1')
print(dataframe2)Método 3: Leer columnas específicas utilizando el parámetro ‘usecols’
# importar librería pandas como pd
import pandas as pd
require_cols = [0, 1, 4]
# leer la primera hoja del excel
dataframe3 = pd.read_excel('C:/tmp/Libro1.xlsx' , usecols = require_cols)
print(dataframe3)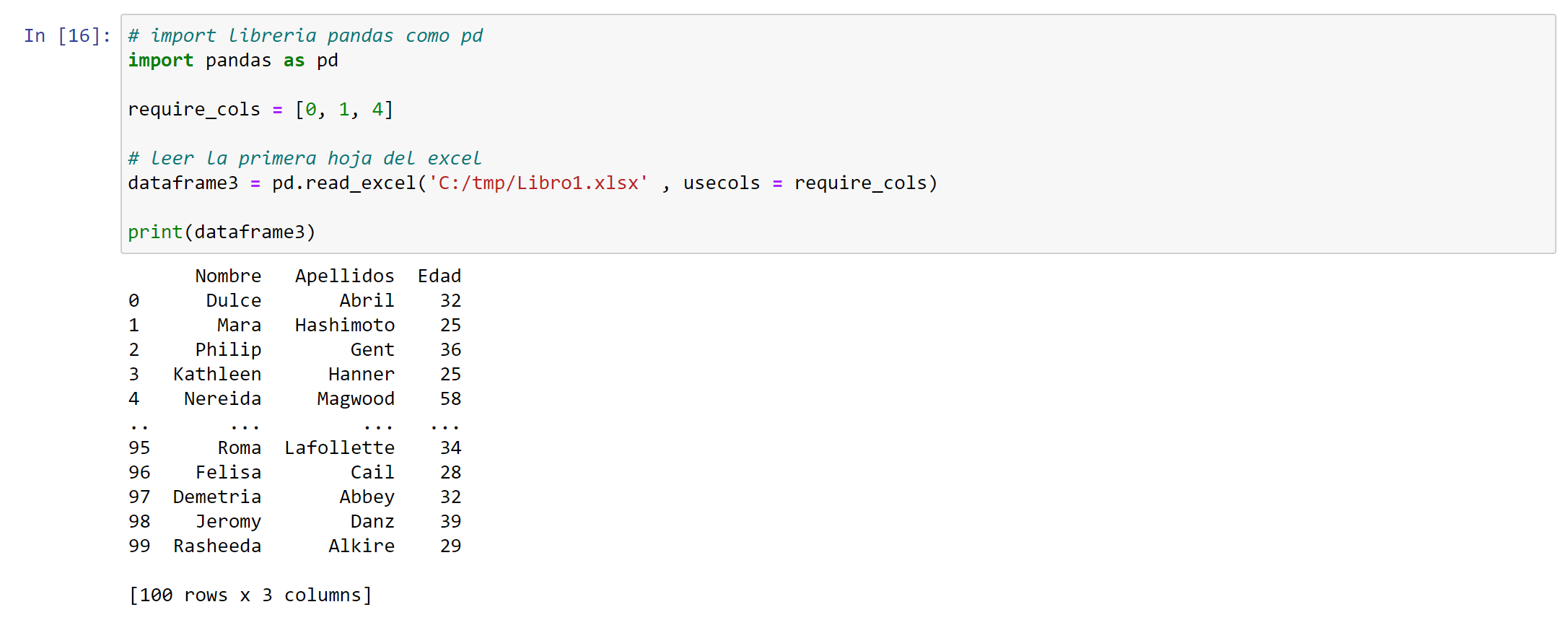
Método 4: Saltarse filas usando ‘skiprows’
# importar librería pandas como pd
import pandas as pd
# saltarse las tres primeras filas
dataframe4 = pd.read_excel('C:/tmp/Libro1.xlsx' , skiprows = 3)
print(dataframe4)Método 5: Establecer la ubicación de la cabecera y leer a partir de ella usando ‘header‘
# importar librería pandas como pd
import pandas as pd
# saltarse las tres primeras filas
dataframe5 = pd.read_excel('C:/tmp/Libro1.xlsx' , header= 2)
print(dataframe5)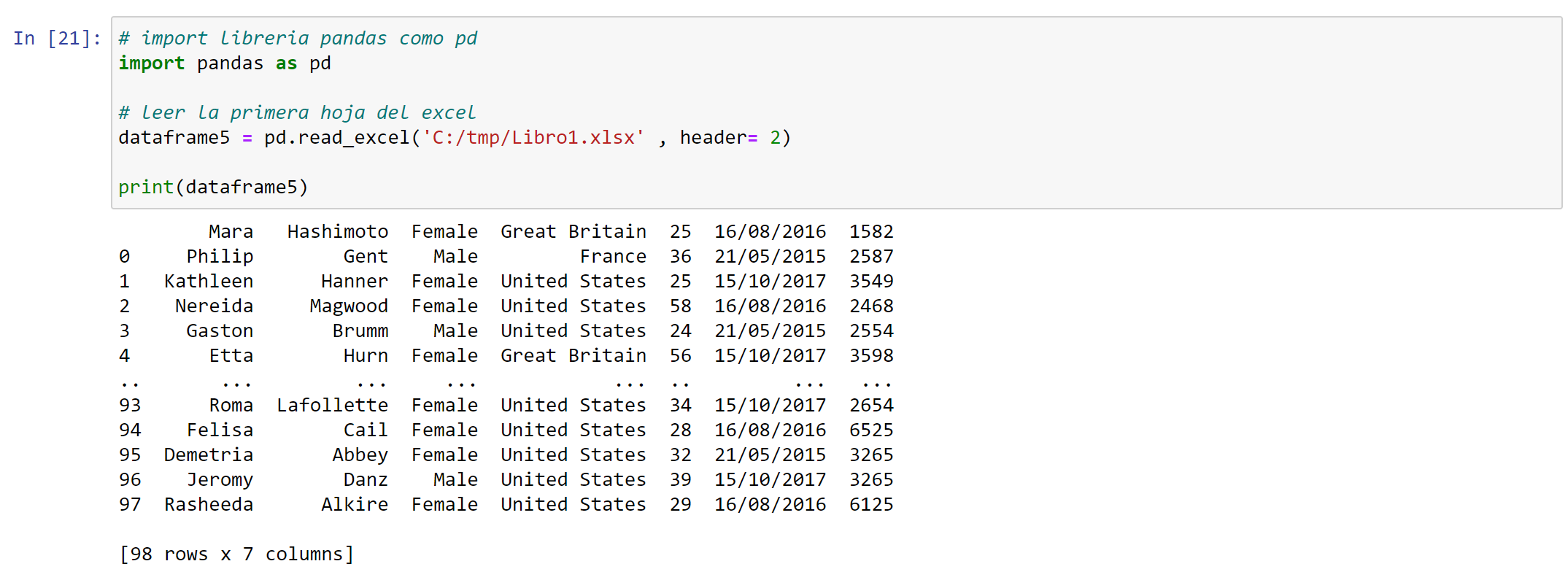
Método 6: Leer varias hojas con ‘sheet_name’
# import libreria pandas como pd
import pandas as pd
# leer varias hojas
dataframe6 = pd.read_excel('C:/tmp/Libro1.xlsx' , sheet_name =['Hoja1', 'Hoja2'])
print(dataframe6)