
En este artículo/ejercicio Notebook y Data Wrangler cargaremos información de ejemplo en un lago de datos desde un cuaderno (Notebook) de Microsoft Fabric, convertimos el dataframe de spark en dataframe de Pandas, visualizaremos datos e iniciaremos Data Wrangler para eliminar duplicados.
Especificaciones del entorno
- Windows 11
- Servicio de Fabric
Paso Previo
En Microsoft Fabric, accede a la ciencia de datos y crea un nuevo bloc de notas:

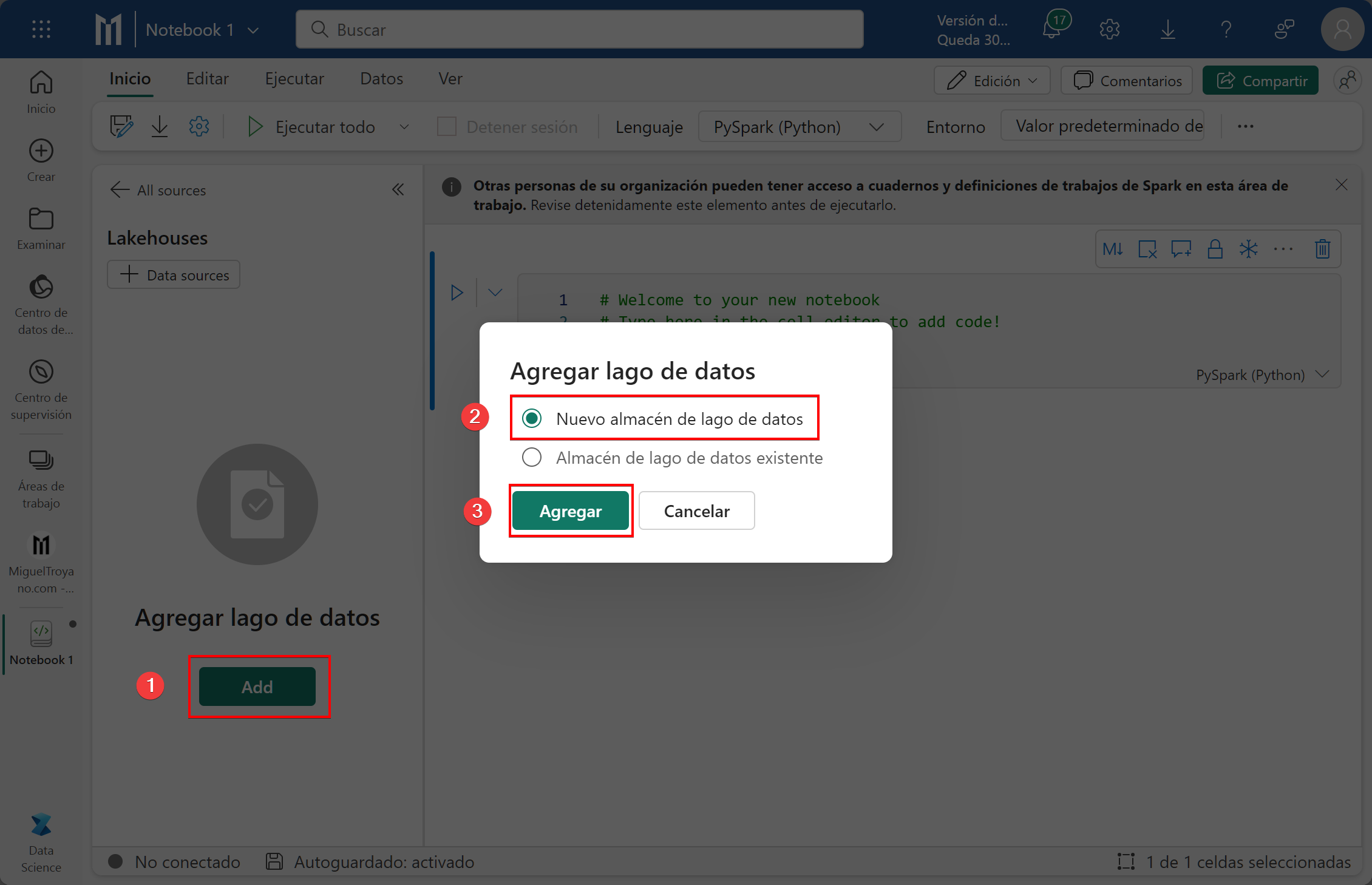
Crear un Lakehouse
Para guardar toda la información necesitaremos un crear un Lakehouse. Partimos del paso anterior donde hemos creado el nuevo bloc de notas.
- Haz clic en Add
- Selecciona la opción Nuevo almacén de lago de datos
- Haz clic en Agregar
- Escribe un nombre al Lakehouse (no puede contener espacios)
Obtener datos
El siguiente paso será descargar un conjunto de datos de ejemplo y cargarlo en nuestro lakehouse anteriormente creado. Para conseguirlo primero estableceremos las variables necesarias para indicar dónde está la ruta del lakehouse, la carpeta donde lo guardará y como se llamara el fichero. Escribe las siguientes líneas en el primer bloque del bloc de notas.
IS_CUSTOM_DATA = False # si es TRUE, el conjunto de datos debe cargarse manualmente
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/churn" # carpeta con los ficheros
DATA_FILE = "churn.csv" # nombre del ficheroUna vez que tenemos las variables ejecutaremos otro bloque donde se descargue los datos de ejemplo. Copia y pega el siguiente ejemplo en otro bloque y ejecutalo todo.
import os, requests
if not IS_CUSTOM_DATA:
# Utilizando synapse blob, esto puede hacerse en una línea
# Descargar archivos de datos de demostración en lakehouse si no existen
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/bankcustomerchurn"
file_list = [DATA_FILE]
download_path = f"{DATA_ROOT}/{DATA_FOLDER}/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"No se ha encontrado la casa del lago predeterminada."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Archivos de datos de demostración descargados en Lakehouse.")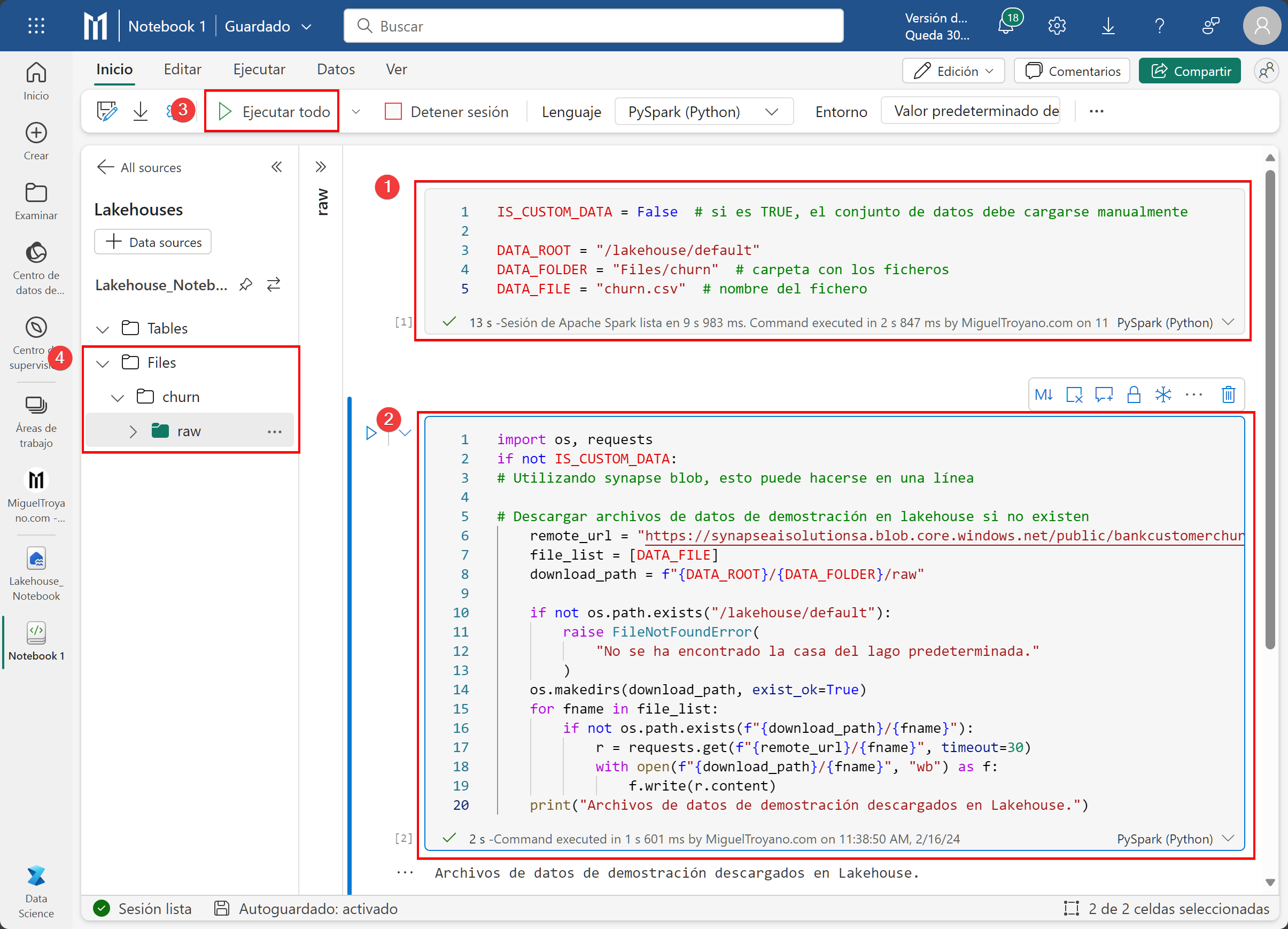
Si después de ejecutar correctamente el código no te aparece el fichero en el Lakehouse (paso 4) posiciónate sobre la carpeta Files y aparecerán tres puntos. Pulsa en los puntos y haz clic en Actualizar.
Leer datos sin procesar
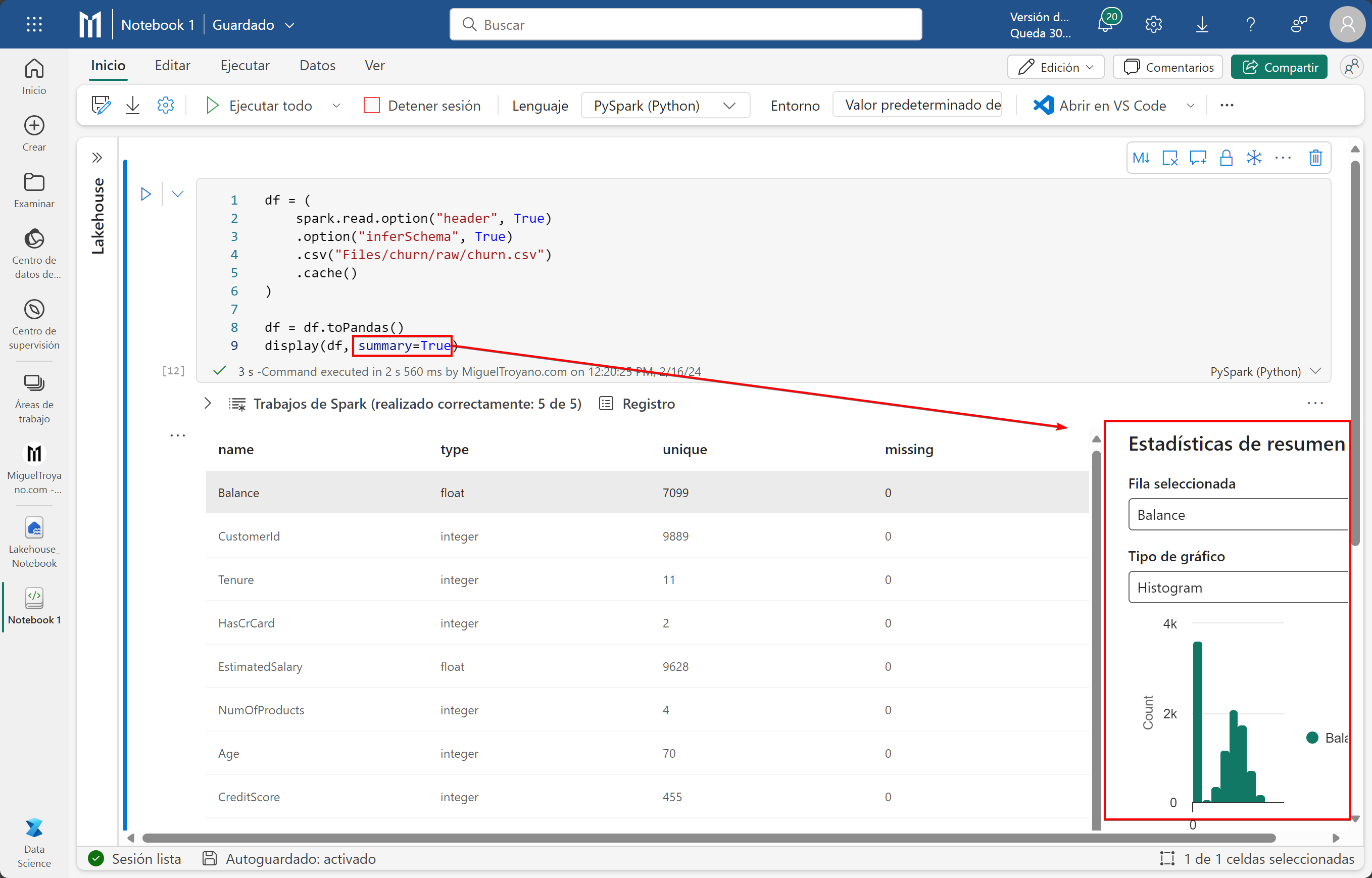
Podemos leer ficheros del Lakehouse directamente sin necesidad de tenerlos en una tabla. Para consultar los datos de un fichero crea la siguiente variable df en un nuevo bloque (puedes eliminar los anteriores) para indicar dónde está el fichero, convertir el dataframe de spark en dataframe de Pandas y mostrar los datos:
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
# Convertimos el dataframe de spark en dataframe de Pandas
df = df.toPandas()
# Mostramos los datos
display(df, summary=True)Cuando utilizamos display para mostrar los datos del dataframe de Pandas no es obligatorio mostrar o escribir el resumen (summary). Si no lo quieres visualizar puedes establecerlo a falso y simplemente eliminarlo y dejar solo display(df).
Limpieza de datos
La limpieza de datos de cualquier dataframe de Pandas se realiza mediante el Data Wrangler (aquí Microsoft nos vuelve locos traduciendo al castellano lo que quiere)

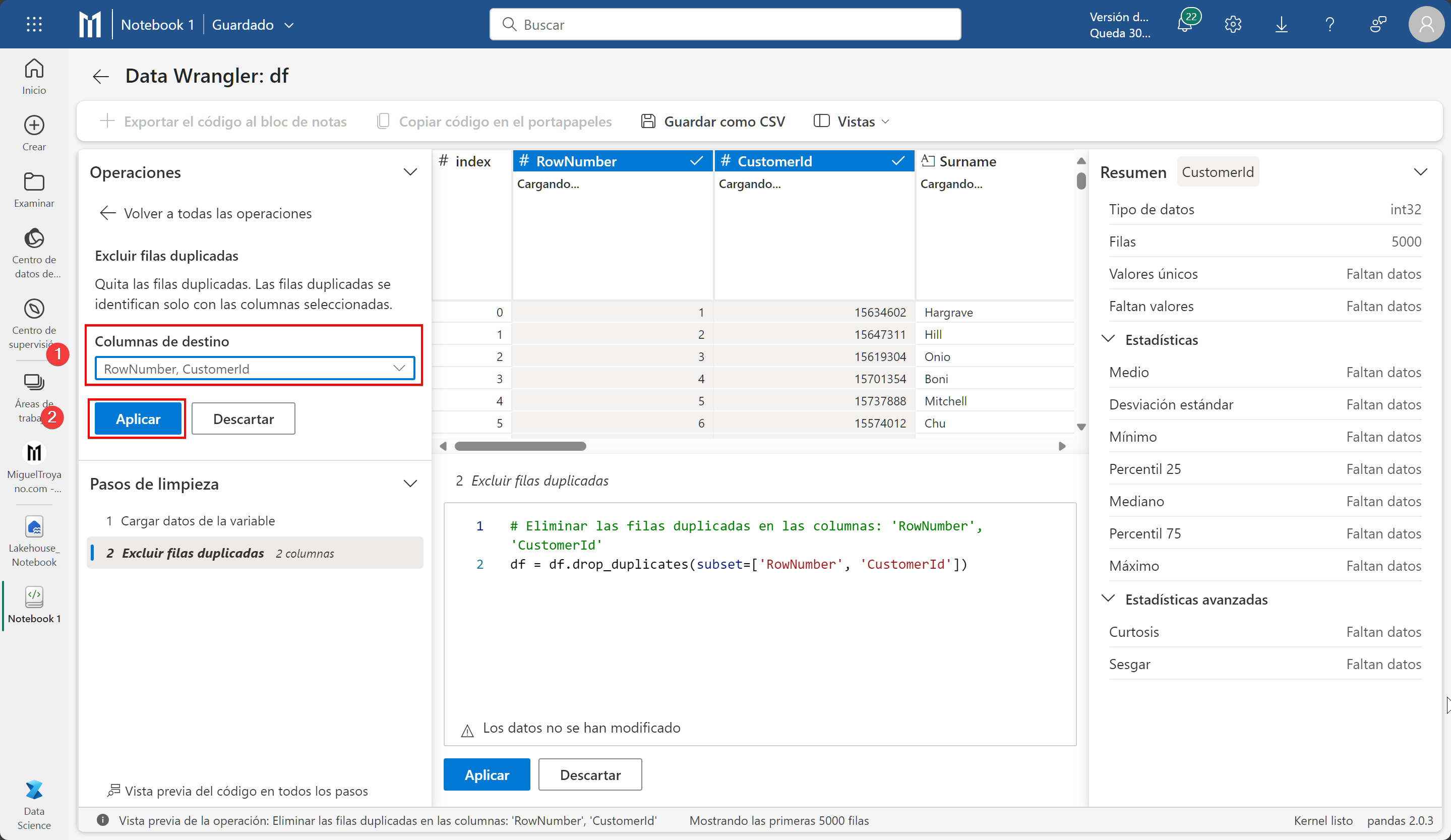
En este cuaderno hemos creado solo un dataframe por lo que cuando hagas clic sobre el botón únicamente te aparecerá nuestra dataframe aunque si tienes varios podrás escoger. Selecciona df que es como se llama nuestro dataframe. Al iniciarse verás una tabla central con los datos, un panel de resumen sobre información relevante del DataFrame. En este ejemplo puedes ver cómo aparece una advertencia en el resumen y en este caso es porque los datos están truncados para el buen funcionamiento de la vista previa. Si seleccionas una columna los datos del panel resumen irán cambiando. En el panel derecho Operaciones, son las diferentes acciones que puedes hacer sobre los datos.
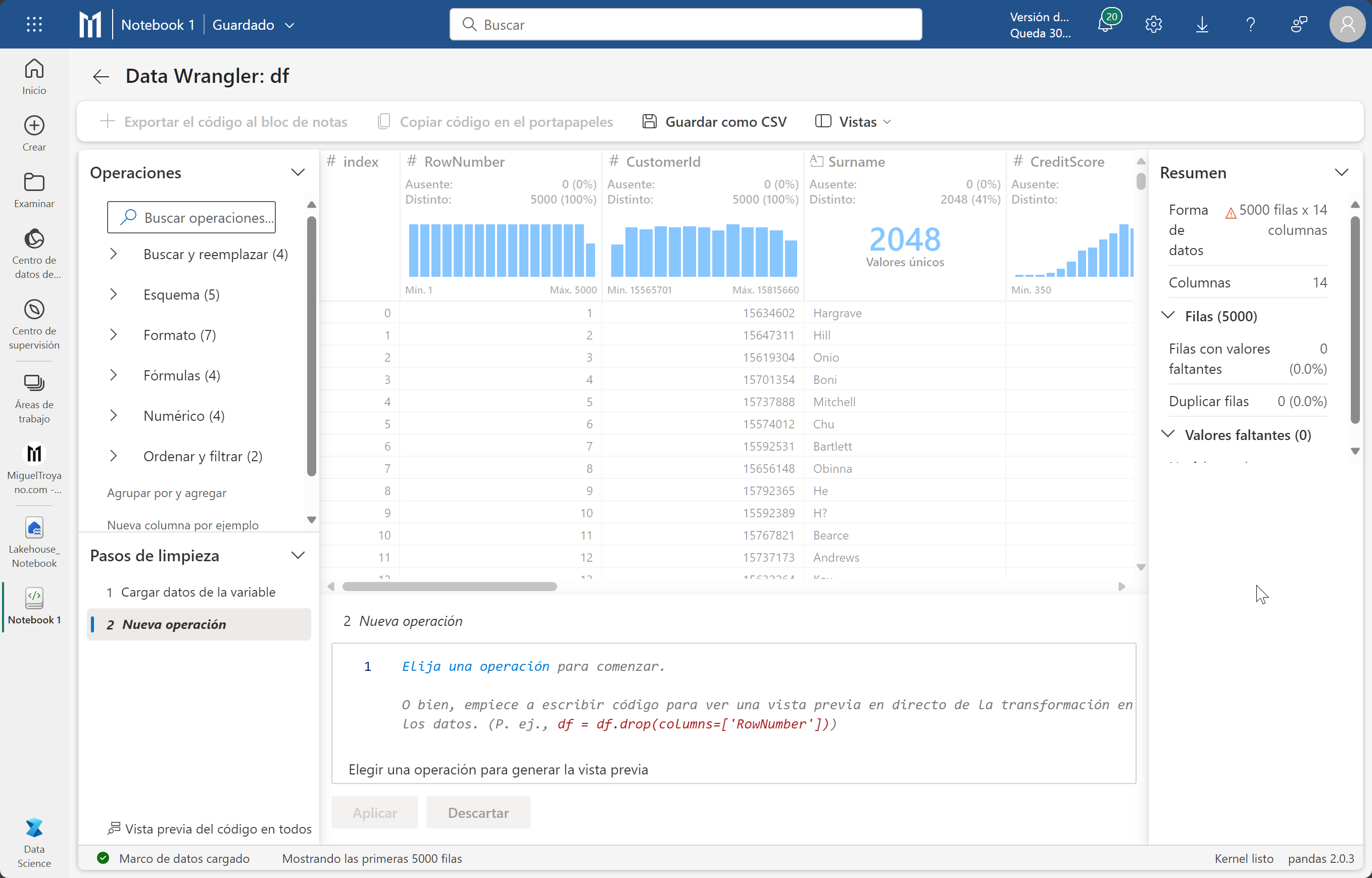
Eliminar duplicados
De este fichero queremos eliminar los datos duplicados para ellos seguimos estos pasos:
- En el panel Operaciones desplegamos Buscar y reemplazar
- Hacemos clic en excluir filas duplicadas.
- No es automático, ahora necesitamos indicarle en que columnas nos vamos a basar para comprobar si hay duplicados. Nosotros seleccionaremos las columnas (no desde el panel central, sino desde el panel de operaciones) rownumber y customerId y aplicaremos. Ten en cuenta que al trabajar con un muestreo de 5000 filas es posible que no notes cambios ahora mismo.
Agregar código al cuaderno
Ahora todos los cambios que hemos realizado necesitamos pasarlos al cuaderno, después de aplicar en el paso anterior pulsa en el menu superior Exportar el código al bloc de notas. Observa como se nos ha generado un código automático:
# Código generado por Data Wrangler para pandas DataFrame
def clean_data(df):
# Eliminar las filas duplicadas en las columnas: 'RowNumber', 'CustomerId'
df = df.drop_duplicates(subset=['RowNumber', 'CustomerId'])
return df
df_clean = clean_data(df.copy())
df_clean.head()