La función REGEXP_INSTR en Oracle mejora la funcionalidad de la función INSTR al permitir buscar una subcadena en una cadena utilizando un patrón de expresión regular. La función REGEXP_INSTR devuelve un valor numérico. Si la función REGEXP_INSTR no encuentra ninguna ocurrencia de patrón, devolverá 0.
Tabla de Contenidos
ocultar
Sintaxis
Escribe la siguiente sintaxis para utilizarlo:
REGEXP_INSTR(
cadena,
patron,
posición,
ocurrencia,
opción_salida,
parametro_coincidencia
)- REGEXP_INSTR: nombre de la función.
- cadena: es la cadena de entrada para buscar el patrón.
- patrón: es una expresión regular. Puede ser una o la combinación de las siguientes expresiones:
| Valor | Descripción |
|---|---|
| ^ | Coincide con el comienzo de una cadena. Si se utiliza con un parámetro de coincidencia de ‘m’, coincide con el inicio de una línea en cualquier lugar dentro de la expresión. |
| $ | Coincide con el final de una cuerda. Si se utiliza con un parámetro match_parameter de ‘m’, coincide con el final de una línea en cualquier lugar dentro de la expresión. |
| * | Coincide con cero o más ocurrencias. |
| + | Coincide con una o más ocurrencias. |
| ? | Coincide con cero o una ocurrencia. |
| . | Coincide con cualquier carácter excepto NULL. |
| | | Se utiliza como un “OR” para especificar más de una alternativa. |
| [ ] | Se utiliza para especificar una lista coincidente en la que intentas hacer coincidir cualquiera de los caracteres de la lista. |
| [^ ] | Se utiliza para especificar una lista no coincidente en la que intentas coincidir cualquier carácter, excepto los de la lista. |
| ( ) | Se utiliza para agrupar expresiones como una subexpresión. |
| {m} | Coincide con m veces. |
| {m,} | Coincide al menos m veces. |
| {m,n} | Coincide al menos m veces, pero no más de n veces. |
| \n | N es un número entre 1 y 9. Coincide con la enésima subexpresión encontrada dentro de ( ) antes de encontrar \n. |
| [..] | Coincide con un elemento de intercalación que puede tener más de un carácter. |
| [::] | Partidos de clases de personajes. |
| [==] | Clases de equivalencia de partidos. |
| \d | Coincide con un carácter de dígito. |
| \D | Coincide con un carácter sin dígito. |
| \w | Coincide con un carácter de palabra. |
| \W | Coincide con un carácter que no sea una palabra. |
| \s | Coincide con un carácter de espacio en blanco. |
| \S | Coincide con un carácter que no sea espacio en blanco. |
| \A | Coincide con el comienzo de una cadena o coincide al final de una cadena antes de un carácter de nueva línea. |
| \Z | Coincidencias al final de una cuerda. |
| *? | Coincide con el patrón anterior cero o más ocurrencias. |
| +? | Coincide con el patrón anterior con una o más ocurrencias. |
| ?? | Coincide con el patrón anterior cero o una ocurrencia. |
| {n}? | Coincide con el patrón anterior n veces. |
| {n,}? | Coincide con el patrón anterior al menos n veces. |
| {n,m}? | Coincide con el patrón anterior al menos n veces, pero no más de m veces. |
- posicion: opcional. Es la posición en la cadena donde comenzará la búsqueda. Si se omite, el valor predeterminado es 1, que es la primera posición en la cadena.
- ocurrencia: opcional. Es la enésima aparición del patrón en la cuerda. Si se omite, el valor predeterminado es 1, que es la primera aparición de patrón en la cadena.
- opción_salida: opcional. Si se proporciona una return_option de 0, se devuelve la posición del primer carácter de la ocurrencia del patrón. Si se proporciona una return_option de 1, se devuelve la posición del carácter después de la ocurrencia del patrón. Si se omite, el valor predeterminado es 0.
- parametro_coincidencia: opcional. Le permite modificar el comportamiento de coincidencia para la función REGEXP_INSTR. Puede ser una combinación de lo siguiente:
| Valor | Descripción |
|---|---|
| ‘c’ | Realiza una coincidencia que distingue entre mayúsculas y minúsculas. |
| ‘i’ | Realiza una coincidencia sin mayúsculas y minúsculas. |
| ‘n’ | Permite que el punto (.), que es el carácter que coincide con cualquier carácter, coincida con el carácter de nueva línea. Si omite este parámetro, entonces el punto (.) no coincide con el carácter de la nueva línea. |
| ‘m’ | La función trata la cadena como varias líneas. La función interpreta el signo de dólar (^) y el signo de dólar ($) como el principio y el final, respectivamente, de cualquier línea en cualquier lugar de la cadena, en lugar de solo al principio o al final de toda la cadena. Si omite este parámetro, la función trata la cadena de origen como una sola línea. |
| ‘x’ | Ignora los caracteres de espacio en blanco. De forma predeterminada, los caracteres de espacio en blanco coinciden entre sí mismos. |
Ejemplo
En el siguiente ejemplo utilizamos la función regex_instr para encontrar la primera posición de la letra ‘m’
SELECT
REGEXP_INSTR ('La web de Miguel es muy moderna', 'm') RESULTADO
FROM
dual;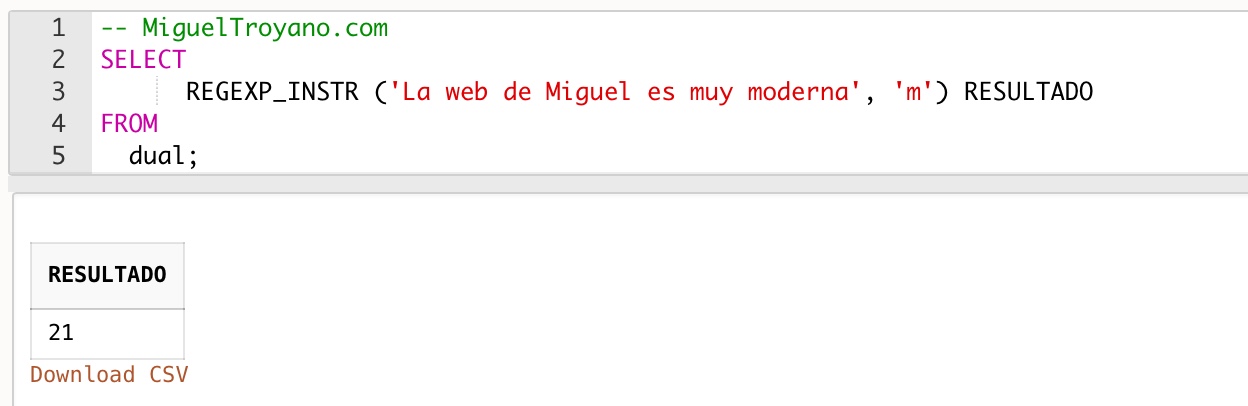
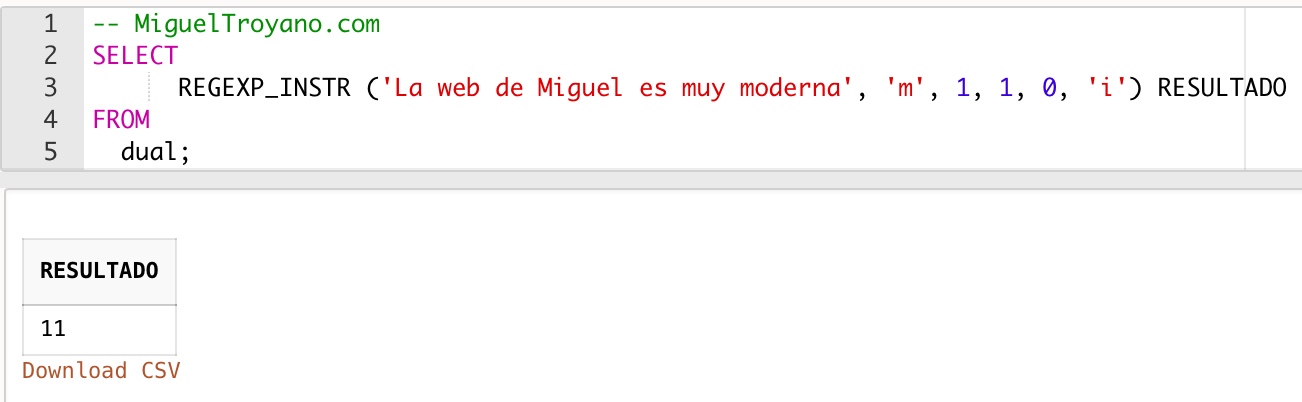
En este otro ejemplo utilizamos la función regex_instr para encontrar la primera posición de la letra ‘m’ indistintamente de si esta escrito en mayusculas o minusculas.
SELECT
REGEXP_INSTR ('La web de Miguel es muy moderna', 'm', 1, 1, 0, 'i') RESULTADO
FROM
dual;