
En este artículo vamos aprender a evitar duplicados usando DISTINCT en PostgreSQL. Esta cláusula se utiliza en la instrucción SELECT para eliminar filas duplicadas de un conjunto de resultados. DISTINCT se queda con un sola fila de cada grupo y es posible aplicarlo a una o más columnas indicadas en el SELECT.
Sintaxis de DISTINCT
La sintaxis básica es:
select distinct columna1
from nombreTabla;
select distinct columna1, columna2
from nombreTabla;En la primera sentencia evalúa los datos de la columna 1 para evitar duplicados mientras que en la segunda evalúa los duplicados en base a la combinación de valores de las dos columnas.
Sintaxis de DISTINCT ON
Si tienes varias columnas en la instrucción SELECT y no quieres aplicar el DISTINCT a todas las columnas puedes usar la cláusula DISTINCT ON. Su sintaxis es la siguiente:
select distinct on (columna1) alias,
columna2
from nombreTabla;
order by columna1, columna2Ejemplos
Usaremos la siguiente tabla llamada empleados para realizar los ejemplos (al final de la página está disponible el script para crearla)

Mostrar los diferentes puestos
Para mostrar los valores diferentes de un campo y así evitar duplicados escribe después del SELECT la palabra DISTINCT seguida del nombre de uno o varios campos:
select distinct puesto
from empleados;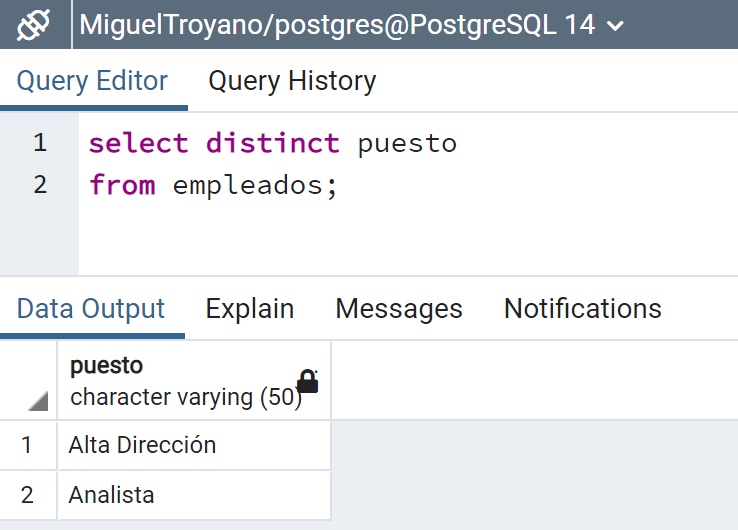
Evitar duplicados de una sola columna
Puedes aplicar DISTINCT a una sola columna usando DISTINCT ON. La consulta te devolverá la primera fila de cada grupo, por ello es muy recomendable usarlo junto a la cláusula ORDER BY para obtener un buen resultado.
En el siguiente ejemplo obtenemos los diferentes puestos y nos quedamos con el primer nombre que encuentre de cada puesto gracias a que hemos indicado que ordene alfabéticamente por nombre ascendente:
select distinct on(puesto) puesto, nombre
from empleados
order by puesto asc, nombre asc;
Ejemplo completo
Copia y pega el siguiente código en tu consola de PostgreSQL y realiza paso a paso leyendo los comentarios.
-- Borramos la tabla si existe
drop table if exists empleados;
-- Creamos la tabla
create table empleados
(
id_empleado numeric(2,0),
id_departamento numeric(2,0),
nombre character varying(50),
puesto character varying(50),
fecha_alta date,
sueldo integer
);
-- Insertamos valores
insert into empleados
values (1,1,'Miguel Troyano','Analista','26/09/1986',60000),
(2,1,'Ismael Troyano','Analista','01/01/2001',60000),
(3,1,'Jose Troyano','Alta Dirección','01/01/2001',80000),
(4,1,'Pilar Redondo','Alta Dirección','02/02/2002',80000);
-- Mostramos los diferentes puestos
select distinct puesto
from empleados;
-- Mostramos el primer nombre que encuentre
-- de cada puesto ordenado ascendentemente
select distinct on(puesto) puesto, nombre
from empleados
order by puesto asc, nombre asc;
-- Mostramos el ultimo nombre que encuentre
-- de cada puesto ordenado descendentemente
select distinct on(puesto) puesto, nombre
from empleados
order by puesto asc, nombre desc;